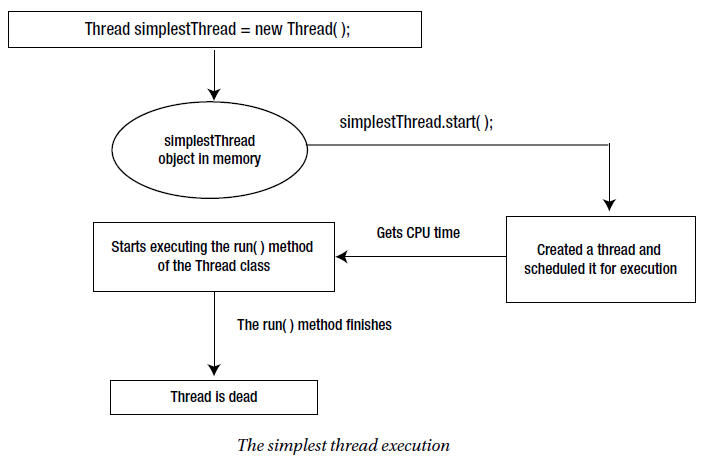
NIO supports file locking to synchronize access to a file. You have the ability to lock a region of a file or the entire file. The file locking mechanism is handled by the operating system and therefore its exact effect is platform-dependent. On some operating systems, a file lock is advisory, whereas on some, it is mandatory. Since it is handled by the operating system, its effect is visible to other programs as well as to Java programs running in other JVMs. In this article, we try to understand this concept with the help of an example.

There are two kinds of file locking:
You cannot mix an exclusive lock and a shared lock on the same region of a file. If a program has a shared lock on a region, another program must wait to get an exclusive lock on that region and vice versa. Some operating systems do not support a shared file lock, and in that case, the request for a shared file lock is converted to a request for an exclusive file lock.
How to represent File Lock
An object of the FileLock class, which is in the java.nio.channels package, represents a file lock. You acquire a lock on a file by using the lock() or tryLock() method of the FileChannel object
Versions of lock() and tryLock() methods
Both lock() and tryLock() methods have two versions: one without an argument and another with three arguments
Different ways of obtaining locks on a file
The exception handling code is omitted for readability.

The file region that you lock may not be contained in the range of the file size. Suppose you have a file with a size of 100 bytes. When you request a lock on this file, you can specify that you want to lock a region of this file starting at byte 11 and covering 5000 bytes. Note that this file contains only 100 bytes; you are locking 5000 bytes. In such a case, if the file size grows beyond 100 bytes, your lock covers the additional region of the file. Suppose you locked 0 to 100 bytes of a 100-byte file. If this file grows to 150 bytes, your lock does not cover the last 50 bytes that was added after you acquired the lock.
The lock() and tryLock() methods of the FileChannel object, where you do not specify any argument, lock a region from 0 to Long.MAX_VALUE of the file. The two method calls fc.lock() and fc.lock(0, Long.MAX_VALUE, false) have the same effect
How to release the lock
When you are done with the file lock, you need to release it by using the release() method.
A file lock is released in three ways:
by calling its release() method, by closing the file channel it is obtained from, and by shutting down the JVM. It is good practice to use a try-catch-finally block to acquire and release a file lock as follows:

Example
In this example, two thread will try to acquire the lock on the same file.
 Sample output
Sample output
File is locked by Thread-0
Thread-1 tried to acquire the lock
lock is released by Thread-0
If you know anyone who has started learning Java, why not help them out! Just share this post with them.Thanks for studying today!...

There are two kinds of file locking:
- Exclusive lock : Only one program can hold an exclusive lock on a region of a file
- Shared lock : Multiple programs can hold shared locks on the same region of a file
You cannot mix an exclusive lock and a shared lock on the same region of a file. If a program has a shared lock on a region, another program must wait to get an exclusive lock on that region and vice versa. Some operating systems do not support a shared file lock, and in that case, the request for a shared file lock is converted to a request for an exclusive file lock.
How to represent File Lock
An object of the FileLock class, which is in the java.nio.channels package, represents a file lock. You acquire a lock on a file by using the lock() or tryLock() method of the FileChannel object
- The lock() method blocks if the lock on the requested region of the file is not available
- The tryLock() method does not block; it returns immediately. It returns an object of the FileLock class if the lock was acquired; otherwise, it returns null.
Versions of lock() and tryLock() methods
Both lock() and tryLock() methods have two versions: one without an argument and another with three arguments
- The version without an argument locks the entire file.
- The version with three arguments accepts the starting position of the region to lock, the number of bytes to lock, and a boolean flag to indicate if the lock is shared. The isShared() method of the FileLock object returns true if the lock is shared; otherwise, it returns false.
Different ways of obtaining locks on a file
The exception handling code is omitted for readability.
The file region that you lock may not be contained in the range of the file size. Suppose you have a file with a size of 100 bytes. When you request a lock on this file, you can specify that you want to lock a region of this file starting at byte 11 and covering 5000 bytes. Note that this file contains only 100 bytes; you are locking 5000 bytes. In such a case, if the file size grows beyond 100 bytes, your lock covers the additional region of the file. Suppose you locked 0 to 100 bytes of a 100-byte file. If this file grows to 150 bytes, your lock does not cover the last 50 bytes that was added after you acquired the lock.
The lock() and tryLock() methods of the FileChannel object, where you do not specify any argument, lock a region from 0 to Long.MAX_VALUE of the file. The two method calls fc.lock() and fc.lock(0, Long.MAX_VALUE, false) have the same effect
How to release the lock
When you are done with the file lock, you need to release it by using the release() method.
A file lock is released in three ways:
by calling its release() method, by closing the file channel it is obtained from, and by shutting down the JVM. It is good practice to use a try-catch-finally block to acquire and release a file lock as follows:
Example
In this example, two thread will try to acquire the lock on the same file.
File is locked by Thread-0
Thread-1 tried to acquire the lock
lock is released by Thread-0
If you know anyone who has started learning Java, why not help them out! Just share this post with them.Thanks for studying today!...